Desarrollo de componentes: Normalización de la base de datos.

Desde mi punto de vista, una de las formas más divertidas e interesantes de trabajar con Joomla! es el desarrollo de componentes. La integración de la arquitectura Modelo-Vista-Controlador, la creciente cantidad de tutoriales para el desarrollo de extensiones, el surgimiento del proyecto Joomla Component Creator y el gran compromiso en los foros de soporte, han facilitado enormemente la creación de componentes tanto para desarrolladores experimentados como para los más novatos. En la práctica, la mayoría de nosotros desarrollamos, como comúnmente se dice, "al vuelo", pero hay parte de la teoría del ciclo de vida de un desarrollo que no debemos dejar olvidada aunque creamos que eso nos quitará tiempo. Uno de esos pasos olvidado por la mayoría de los tutoriales, es la Normalización de la Base de Datos. ¿Qué es?¿Para qué sirve?¿Cómo se hace? Trataré de ser breve.
Las versiones más recientes de Joomla! han tenido una gran mejora en cuanto a la normalización de su base de datos lo que le brinda muchos beneficios: mayor rapidez, mejor indexación (de las tablas) e incluso mayor seguridad. Es de esperarse entonces que nuestros desarrollos incluyan una base de datos que cumpla con estos principios.
Pero ¿qué es la Normalización de bases de datos? Se podría escribir un libro completo sobre el tema, pero trataré de explicarlo de una forma sencilla y tan breve como sea posible .
La Normalización es un proceso que consiste en aplicar una serie de reglas que nos permitirán organizar nuestra base de datos evitando la redundancia, garantizando la integridad de nuestra información. Para avanzar en el proceso de la Normalización, debemos ir dividiendo nuestras tablas en dos o más (sin perder la relación entre ellas).
Tener nuestra base de datos correctamente relacionada y normalizada nos evitará redundancia de datos (en términos prácticos, datos repetidos) y nos ayudará a tener una base de datos más "ligera", más correcta y tiempos de ejecución menores.
En muchos casos, cuando tu componente no involucra grandes cantidades de datos, normalizar la base de datos, no es considerado una prioridad, pero es bueno que recuerdes que tu componente formará parte de un todo con Joomla! y es bueno tener nuestros datos lo mejor estructurados que se pueda.
Debo mencionar que este artículo no hubiera sido posible sin la asesoría y correcciones de Leonel Canton, conocedor del tema y fundador del JUG Guatemala.
Para explicar el proceso que debes seguir para normalizar tu base de datos, partamos de un ejemplo real. Supongamos que necesitamos hacer un componente para una biblioteca que llevará el control de préstamos de libros.
Un paso previo que muchos desarrolladores obvian al realizar sus componentes es la realización de un Diagrama ENTIDAD-RELACIÓN. Este diagrama es una herramienta que nos permite visualizar de forma clara la cantidad de entidades que necesitamos así como las relaciones que existen entre ellos. Esto junto a la forma en que se desee que el componente se comporte (reglas del negocio) nos permitirán definir las tablas que realmente se crearán así como los atributos de cada una de ellas y en particular la llave primaria. En este paso vale la pena tomar papel, lápiz y no olvides un borrador, ahora a dibujar. Sigamos con nuestro ejemplo:
¿Sabemos cómo debería funcionar nuestro componente? ¿Qué es lo mínimo que debe hacer?:
- "Un usuario solicita un préstamo".
- "Un préstamo incluye uno o varios libros".
Estas frases tiene dos objetivos muy claros, el primero es identificar las entidades y relaciones. Definimos una entidad como todo aquello que tiene vida propia (sustantivo) y relación como la forma en que una entidad interactúa como otros (verbos).
| Entidades | Relaciones |
|
|
El segundo objetivo es identificar la forma en que interactúan las entidades con las relaciones, observemos las palabras "UNO" o "VARIOS". Dos entidades pueden participar en una relación en cualquiera de las siguientes formas:
- Uno a uno (1:1). Cada entidad A se relaciona solo con 1 entidad B
- Uno a varios (1:N) Cada entidad A se relaciona con Muchas entidades B
- Varios a uno (N:1) Muchas entidades A se relacionan con 1 entidad B
- Varios a varios. (N:M) Muchas entidades A se relacionan con Muchas entidades B
Con esto en mente podemos identificar los elementos que nos permitirán diferenciar un dato de otro, nuestras llaves primarias.
- USUARIOS -> Id_usuario
- LIBROS -> ISBN
- PRÉSTAMOS -> Id_prestamo
Ya identificado todo esto, sólo nos falta dibujar nuestro diagrama ENTIDAD-RELACIÓN.
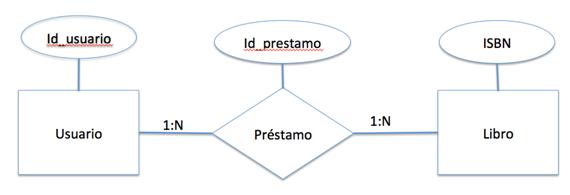
Se puede decir mucho al momento de trasladar un diagrama ENTIDAD-RELACIÓN a su representación en tablas, pero me limitaré a comentar que cada rectángulo y rombo es convertido en una tabla, claro que luego de esto empezamos a optimizar, dependiendo de la participación de la entidad en dicha relación, así como si nos interesa o no guardar cierto grado de historiales. Otro detalle importante a considerar es que en cada rombo se debe agregar las llaves primarias de todos los rectángulos que llegan a este.
Antes de empezar con la normalización, solo nos hace falta determinar la información adicional que deseamos almacenar sobre cada una de las entidades y relaciones que hemos determinado. Al hacer esto es bien importante definir bien la forma en que se almacenarán los datos, y esto depende de lo que necesitemos hacer, ya que no es lo mismo la dirección de un contacto que la misma dirección vista por una empresa de envió de paquetes.
Identifiquemos pues los atributos de nuestras tablas:
- USUARIOS: id_usuario, nombre, edad, fecha de nacimiento, correo eletrónico, dirección, teléfono casa, teléfono móvil
- PRESTAMOS: id_prestamo, id_usuario, fecha, ISBN, fecha de entrega.
- LIBROS: ISBN, título, materia, autor, nacionalidad_autor
Como comenté antes, la normalización consiste en aplicar reglas (Formas Normales) que nos ayudarán a relacionar mejor nuestras tablas para evitar repeticiones y hacerla más eficiente.
Lo primero que hay que hacer es identificar las DEPENDENCIAS de cada uno de los atributos que hemos definido para nuestras entidades para ir descomponiéndolos en partes más pequeñas según las Formas Normales.
Ahora lo divertido. La Normalización en sí. Existen 5 reglas o Formas Normales que aplicar. Sin embargo, la mayoría de las bases de datos sólo requerirán de las 3 primeras que son las que aplicaremos en nuestro ejemplo.
Identificar las DEPENDENCIAS es clave para normalizar. Estas dependencias son de muchos tipos pero por el momento basta con buscar de qué manera depende unos atributos de otros. Por ejemplo. En USUARIOS tenemos dos campos que tienen una DEPENDENCIA FUNCIONAL que es el tipo de dependencia más común a identificar: edad y fecha de nacimiento. Al saber la fecha de nacimiento podemos identificar la edad de una persona, este segundo atributo (edad) puede ser eliminado sin que eso represente una alteración importante ni la pérdida de información.
Primera Forma Normal (1NF).
En esta etapa debemos asegurarnos de que todos nuestras campos son únicos (atómicos) e indivisibles y eliminar todos los datos que sean repetidos o que tengan una dependencia funcional, como el ejemplo de edad y fecha de nacimiento.
Ejemplo. En nuestra tabla de usuarios deberíamos.
- Eliminar el atributo edad, pues depende directamente de fecha de nacimiento.
- Como puedes notar tenemos dos campos para almacenar teléfonos: teléfono de casa y teléfono móvil. ¿Qué pasaria si después tenemos la necesidad de almacenar un tercer teléfono, por ejemplo un fax? En lugar de tener que modificar la tabla y el componente, deberíamos agregar entonces una tabla más denominada "teléfonos" en donde identificaríamos el número de teléfono, el tipo, y el id del usuario relacionado a cada caso. El componente entonces tendría que identificar los teléfonos de un determinado usuario, sea 1 o sean varios (relación 1:N). Nuestra tabla de usuarios se dividiría como sigue:
TABLA 'USUARIOS':
|
id_usuario |
nombre |
fecha_de_nacimiento |
correo_electronico |
direccion |
TABLA 'TELEFONOS':
|
id_telefono |
id_usuario |
telefono |
tipo |
Nota que ahora en la tabla "telefonos" tienes dos tipos de clave: una principal o maestra y una foránea que te ayudará a identificar a qué usuario pertenece cada teléfono.
Segunda Forma Normal (2FN).
En la segunda forma normal debemos eliminar la redundancia que se pueda observar, esto lo hacemos si al revisar las dependencias funcionales existentes notamos que un subconjunto de nuestra tabla no depende de la llave en su totalidad (dependencia parcial de la llave). Para lograr esto debemos crear una tabla independiente para estos valores incluyendo algún campo que nos permita relacionarlo con la tabla original.
En nuestro ejemplo tenemos la tabla PRÉSTAMOS. Ya aplicada la 1FN, nuestra tabla tendría los siguientes campos con algunos registros de ejemplo.
TABLA 'PRESTAMOS' 1NF
|
id_prestamo |
id_usuario |
ISBN |
fecha |
fecha_entrega |
|
1 |
1 |
00001 |
2013-01-01 |
2013-01-15 |
|
1 |
1 |
00032 |
2013-01-01 |
2013-01-15 |
|
1 |
1 |
0005 |
2013-01-01 |
2013-01-15 |
|
2 |
2 |
00001 |
2013-01-18 |
2013-01-30 |
Si observamos, identificamos cada préstamo con un id único, pero éste se repite, pues si recordamos la relación, un usuario puede solicitar 1 o varios libros en cada préstamo (Los datos solo sirven para mostrar la redundancia, no debemos olvidar que es importante validar que esto es cierto verificando las reglas del negocio de nuestro componente o desarrollo en general). Si almacenamos esto en una sola tabla, tenemos redundancia. La solución es crear tablas independientes, una con los datos del préstamo y otra con los libros de ese préstamo:
TABLA ‘PRESTAMOS’ 2FN
|
id_prestamo |
id_usuario |
fecha |
fecha_entrega |
|
1 |
1 |
2013-01-01 |
2013-01-13 |
|
2 |
2 |
2013-01-18 |
2013-01-30 |
TABLA ‘RESIGTROS_PRESTAMOS’ 2FN
|
id_registro |
id_prestamo |
ISBN |
|
1 |
1 |
00001 |
|
2 |
1 |
00032 |
|
3 |
1 |
0005 |
|
4 |
2 |
00001 |
Tercera Forma Normal (3FN)
En la tercera forma normal, debemos eliminar de las tablas los datos que no dependan directamente de la clave de la tabla. Es decir, si la tabla contiene datos sobre un libro debemos quitar de la tabla los datos que no correspondan directamente con el libro, por ejemplo:
La tabla LIBROS contiene los campos: ISBN, titulo, materia, autor, nacionalidad_autor
Aplicando 1FN y 2FN tendremos tres tablas.
TABLA ‘LIBROS’ 2FN
|
ISBN |
titulo |
id_materia |
id_autor |
nacionalidad_autor |
Las siguientes tablas fueron creadas ya que tanto las materias como el nombre del autor se repetían en la tabla libros, y si dejamos esos textos en la tabla, se corre el riesgo de que el usuario los ingrese a su antojo, una vez con todo mayúscula, la siguiente solo con la inicial mayúscula y una última con iniciales en lugar del nombre completo.
TABLA ‘MATERIAS’ 2FN
|
id_materia |
nombre_materia |
TABLA ‘AUTORES’ (2FN)
|
id_autor |
nombre_autor |
Si notas, la nacionalidad del autor no es un campo que dependa directamente de libro, sino que es una dependencia del autor por lo que en nuestra tercera forma normal tendríamos que mover ese campo a una nueva tabla, aunque en este caso ya tenemos la tabla a la que corresponde:
TABLA ‘LIBOS’ (3FN)
|
ISBN |
titulo |
id_materia |
id_autor |
TABLA ‘AUTORES’ (3FN)
|
id_autor |
nombre_autor |
nacionalidad |
TABLA ‘MATERIAS’ (3FN)
|
id_materia |
nombre_materia |
Existen varias formas normales adicionales, por ejemplo la conocido como Forma Normal de Boyce-Codd (para algunos autores equivale a 3.5). La cuarta, quinta y sexta forma normal fueron diseñadas para condiciones muy puntuales y están fuera del alcance de este artículo
Si observamos nuestras base de datos vemos que de tres tablas que teníamos originalmente terminamos con 7:
- USUARIOS
- TELÉFONOS
- PRÉSTAMOS
- RESIGTROS_PRESTAMOS
- LIBROS
- AUTORES
- MATERIAS
Y podríamos ir más lejos, si por ejemplo descomponemos el campo ‘dirección’ de la tabla USUARIOS pensando que el usuario podría tener más de una dirección y a su vez cada dirección contendría un país (de una tabla de países), un estado (extraído de una tabla de estados), etc. Depende mucho, desde luego, de las necesidades de cada desarrollo.
En este punto hay que notar lo siguiente. IMPORTANTE.
Nuestro componente tiene una tabla de usuarios. Estos usuarios, ¿cómo los vamos a relacionar con los usuarios de Joomla!?
Joomla ya tiene una tabla de usuarios ( #_users ), en nuestro caso debemos adaptar nuestra pequeña porción de base de datos a la de Joomla!. La tabla de usuarios de Joomla! ya contiene algunos de los datos que nosotros necesitamos, por lo que tendríamos que quitarlos de nuestra tabla de usuarios. La forma de unirlas sería por medio de una clave foránea que haría referencia a la clave maestra de usuarios de Joomla!:
TABLA ‘USUARIOS’
|
id_usuario |
joomla_user_id |
dirección |
fecha_de_nacimiento |
Conclusiones:
La Normalización es un paso fundamental ante cualquier desarrollo de software que involucre una base de datos, y un desarrollo de componentes de Joomla! no debería ser la excepción pues esto nos garantiza que estamos desarrollando un componente no solamente compatible sino además eficiente.
La Normalización de bases de datos es un tema muy extenso. En el desarrollo de componentes pequeños no se requiere profundizar tanto, pero realmente vale la pena tomarse el tiempo para estudiar a profundidad, sobre todo si se realizan desarrollo más robustos.
Con una base de datos bien Normalizada aseguramos en más del 50% el buen funcionamiento de nuestro componente pues si los datos están bien estructurados la programación del componente será más fácil y ordenada. Ahora sí, ! a programar!
Espero que este artículo sea de utilidad y espero también sus comentarios . Será muy grato leerlos.
Sobre el autor
By accepting you will be accessing a service provided by a third-party external to https://magazine.joomla.org/
Comentarios