
Rebasing

If you think this involves a teaspoon and a spirit lamp, take your F and go home. Git's "rebase" command takes advantage of the distributed nature of git to enable you to do some really useful and creative things in your repository. Of course, like all power tools, rebase can be abused. Let's take a closer look at what can be done through rebasing, and where and when you should use it. This article assumes familiarity with software version control systems in general, as well as a basic familiarity with git itself. While it does explore some git fundamentals, it is not intended to be a primer on git usage.
Git is a distributed version control system. This means that while it can be used in the same manner as centralized code repositories like subversion, it is also capable of working with several different repositories for the same source code, at the same time.
Because these multiple repositories will not all be in the same state at any point in time, it has built-in tools to synchronize across repositories, and co-ordinate the work of team members scattered across the globe.
Git-ting the Fundamentals
Think of a git repository as a map, made up of nodes and pathways. The nodes are snapshots of the condition of the code, created after every commit. The pathways are a diff file that can be applied to one node to move to another.
The nodes are identified by references. Every commit has an ID, that's a reference pointing at a node. And when you create a tag, that also is a reference. Plus, git itself has some references (such as HEAD, a reference that always points to the top of the current source branch).
If you start thinking of the repository as a map of your code, you can see now how everything can be fluid. A reference can easily be created, or removed, simply by creating or merging pathways. Rebase takes advantage of that fluidity, allowing you to re-map your code repository.
Simple Rebase
The simplest form of rebase is the "git rebase branch name" command. It takes the current branch and remaps it so the branching point is the HEAD of the given branch.
Imagine a master branch with two commits. You start working on a new feature, so you create a dedicated branch at that point (we'll call it "Feature") and start working.
At the same time, other members of the team make some more commits to the master branch, fixing some serious bugs. Your Feature branch could profit from those bug fixes, so you want to incorporate them into it. Your repository map might look something like this ("C1" to "C6" represent the commits, the nodes in the map):
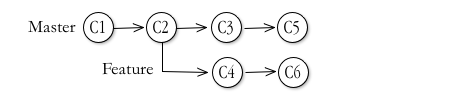
You could cherry-pick individual commits from master into your branch, or you could merge master into your branch. Either one will pick up the fixes. But they will also create commits in your Feature branch that aren't strictly speaking, part of the feature itself, and which you'll have to work around later, especially if it happens often.
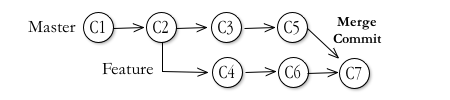
Or you could:
git checkout Feature git rebase master
Now the repository map looks like this:
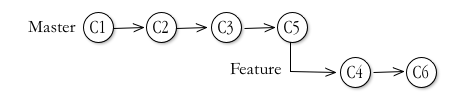
It's a much cleaner and more understandable map of the repository. It shows the Feature branch, containing only commits pertaining to the feature, yet including all the modifications and bugfixes approved for the master branch.
That's A Lie!
Yes, if you think the repository log should be an audit trail, a historical record of what happened, it is a lie. But if you think of the repository log as a map to the code, it's not a lie. It shows the Feature branch resting on a fully up-to-date master branch, as it is. So it shows the truth of where you are, and shows it more clearly than the merge would, just not how you got there. Your opinion on the worth of a simple rebase rests on whether you think it's better to have a clear picture of where you currently are, or a detailed and accurate record of where you've been. You decide that for yourself; I'm just the tour guide.
Can I Have Some More, Please?
A little more complex, and more useful, is a rebase on pull. For this, imagine your own local master branch is your local copy of the master branch in a public repository. We'll call that remote branch "origin" and we'll assume that other members of your team are also pushing changes (or submitting pull requests, however you care to flow the work) into it, which you pull down to your local repository to keep it up to date.
You could bring your Feature branch current with the public master with:
git checkout Feature git pull origin
which ends up with a map that looks like this:
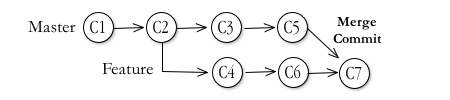
There's an extra merge commit, connecting origin to Feature, right at the head of Feature. After 6-7 of these operations, you can guess how cluttered the repository map will become.
But aside from that, there's another danger. Let's say after a couple of these, you discover something seriously wrong in your approach (or the definition of this feature gets extensively changed). Now you'll have to roll back some of your commits to get to a better place to start the new coding from.
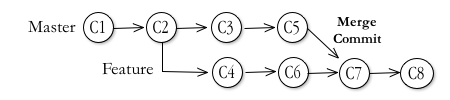
If that new point is back before any of the merges (for example, if you need to roll back from C8 to C6 in the above figure) your Feature branch will lose access to the updates made to the public repository that were merged by that commit. Meaning you'll have to merge them in yet again. Rinse. Lather. Repeat.
Instead, you could have brought the changes from the public repository in with a rebase:
git checkout Feature git pull --rebase origin
which ends up with a repository map that looks like this:
No merge commit, and you can roll back as far as you need to in your Feature branch without ever having to re-merge with the remote repository. The repository map is nice and clean, and all the code in your Feature branch is code you wrote specifically for the feature.
Which in turn means it'll be easier for your to create a pull request of the Feature branch when it's done. (Speaking of which, what is taking you so long with that feature, anyway?)
Git-ting Interactive On Your Base
OK, now we've seen some of the basics of rebase, let's take a look at its most complex and deadly form -- the interactive rebase:
git rebase -i reference
The reference given could be any reference in the map, or any of the built-in references, such as HEAD. For example, "git rebase -i HEAD^^^" will start the interactive rebase using the last three commits, while "git rebase -i fe40861" will rebase all the commits since the commit labeled "fe40861."
When you enter the interactive rebase command, git will respond by putting text similar to the following in your default editor:
pick 33fde07 Make some declarations align pick 953683a Don't align function arguments. pick 904e0b8 Correcting issue 26493 pick 06b98bd Add function to batch edit an item's language pick f4b68ea Correcting issue pick 10b14bf Fixed JDaemonTest # Rebase fe40861..10b14bf onto fe40861 # # Commands: # p, pick = use commit # r, reword = use commit, but edit the commit message # e, edit = use commit, but stop for amending # s, squash = use commit, but meld into previous commit # f, fixup = like "squash", but discard this commit's log message # x, exec = run command (the rest of the line) using shell # # If you remove a line here THAT COMMIT WILL BE LOST. # However, if you remove everything, the rebase will be aborted. #
The first lines (lines beginning with "pick …" above) are a list of the individual commits that will be included in this rebase. You can rearrange the list of commits in any new order you want for them. The "pick" is a command that tells git that you want to accept this commit exactly as it currently is.
The next most useful command is "squash." That command tells git you want to combine this commit with the one above it, turning two commits into one. You might want to use this, for example, if you accidentally included an error in the previous commit that you didn't catch until sometime after the commit. The fix has no meaning in this context, because the erroroneous code isn't a valid "stop" on your map through the code, so bundling it with the fix makes life simpler for those who come after you, they don't have to wade through meaningless commits and can revert the intended code change by only reverting one commit.
The rest of the commands are pretty self-explanatory, except perhaps "edit," which gives you some really powerful options, which I'll explain shortly.
After you've rearranged the list of commits, if you need to, and set up the commands, git will start the rebasing.
If you've given the edit command, git will stop when it comes to it, giving you the opportunity to enter in any commands you wish before continuing. Git will give you a prompt at the command line similar to:
Stopped at commitID… commit log message You can amend the commit now, with git commit --amend Once you are satisfied with your changes, run git rebase --continue
Remember we said git ttracks individual changes? At this point you could enter
git reset HEAD
to pull the changes staged for this commit out of the staging area. You could then go ahead and stage individual changes from a file into a separate commit, commit it, and then stage the rest of the changes and commit them, turning a single commit into two. Then, when you're done with whatever you need to do at this stage, you enter the command "git rebase --continue" and git will continue on with the rebasing until finished, or until it encounters another command that needs interaction from you.
Why would you do something like this? Let's say you've had your head down, coding along the Feature branch, and while you're doing it you notice and fix a bug in one of the files you're touching. After you've committed your changes, you realize the fix itself should have been a separate commit, maybe because one of your team has just run across something similar in the feature they're working on. This allows you to go back and split that change out of its original commit, making it easily available to be pulled into other branches either with cherry picks or merges or other rebase operations.
So Time Can Be Rewritten?
In the sense that the repository log is viewed as time, yes. You can move events around in the repository stream at will. And yes, that can be as dangerous and confusing as you think it is. Which means There Are Rules.
The first rule for safe use of rebase is never rebase a public repository (a public repository is one used by more people than just you). I SAID, NEVER REBASE A PUBLIC REPOSITORY! People other than you rely on a public repository, and if you change the history there, it will throw everyone else's repository out of sync, causing everyone problems. Never, ever (no, not even when the Pandorica opens) rebase a public repository.
As for your own repository, you can rebase that whenever, but just because you can is not a good reason. Think of rebasing as a refactoring tool for your repository. Only do it when the result will make things cleaner and easier to use and understand.
Examples of this might be to group several little commits into a bigger one, a unified whole. This is useful when there really is no reason to revery one of the changes without reverting the others as well. How often this happens depends upon your work style.
Some people treat commits like a precious resource, and only commit code when they have something useful and significant to commit. People who use that work style won't see the above as an opportunity. Others, like me, treat commits as one step up from a "save". It's not unusual for me to make 5 or even more commits while working on a single issue (if it's been more than half an hour since my last commit, my hands start to shake and I start to think about what I might lose if I don't commit RIGHT NOW). I commit like Chicago votes -- early and often.
Other opportunities for rebasing come when changes get made in the branch you have branched off of. They might be useful in your own branch, but aren't strictly speaking part of the feature itself.
Oops
Use git rebase like any other power tool -- carefully. But no matter how careful you are, Murphy has a way of making things go pear-shaped.
If you're doing some interactive rebasing ('git rebase -i') it's possible you'll see an error message like "interactive rebase already started." This means git is already in the middle of an interactive rebase. If you know it is, and you know the rebase is still good, 'git rebase --continue' will get you back on track. If you're not sure, you can use 'git rebase --abort' to scrap the entire rebase.
Git always labels the starting point for a rebase with the reference ORIG_HEAD, so if after a rebase you're not comfortable with where you're at, try 'git reset --hard ORIG_HEAD' to return you to a better place.
ORIG_HEAD can be useful in other ways, as well. You can use 'git diff ORIG_HEAD..HEAD to see the sum total of the changes made by a given rebase operation.
Rebasing is a feature of git that makes it an even more powerful development tool. Play around with it a little, get to know where it fits in your tool box, and it'll make your life easier.
Some articles published on the Joomla Community Magazine represent the personal opinion or experience of the Author on the specific topic and might not be aligned to the official position of the Joomla Project
About the author
By accepting you will be accessing a service provided by a third-party external to https://magazine.joomla.org/
Comments