
Why Simple Structured Data (Microdata, RDFa) isn’t so Simple

This article will take a closer look at the problems and solutions related to Microdata and RDFa and why a simple problem isn't so simple.
Introduction
First of all, let's understand why we need Structured Data such as Microdata and RDFa, and their uses. Let suppose you have a web page containing the word ‘Jaguar’ inside the content, at this point a human who is reading the article can understand based on the context if the word ‘Jaguar’ identifies an animal or a brand of car. Unfortunately the machines (computers) currently can’t understand automatically the difference, because it doesn't know the context in which the words are used. So this is the reason why we insert Structured Data manually, to provide contextual information to machines about our content.. This means that a human needs to manually add additional information to explain to a machine what the page talking about!
Why do we need to machines to know what the what the page is about? One reason is that search engines such as Google use that information to display Rich Snippets in the SERP (Search Engine Result Page).
Problems
In order to manually add structured data, you need to be skilled in HTML, SEO (Search Engine Optimisation) and Microdata / RDFa, but not everyone has these skills. Users with different roles have different skills. Now let’s analyse all the problems and see how we could implement and add in an automatic way this type of information.
Problem one:
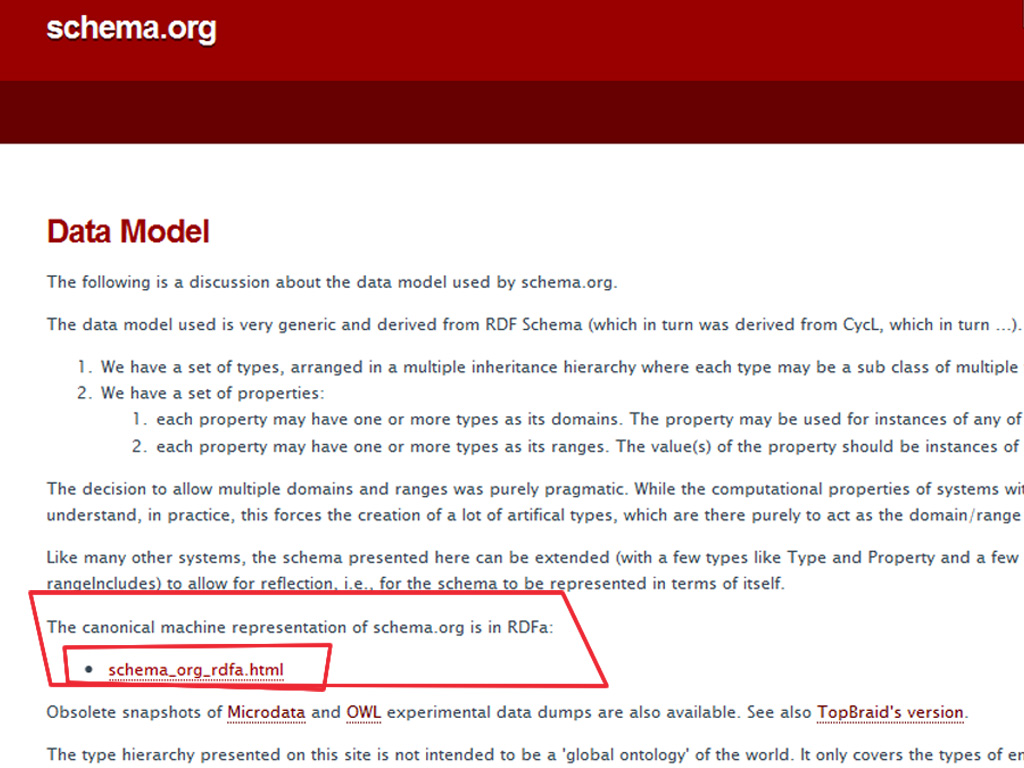
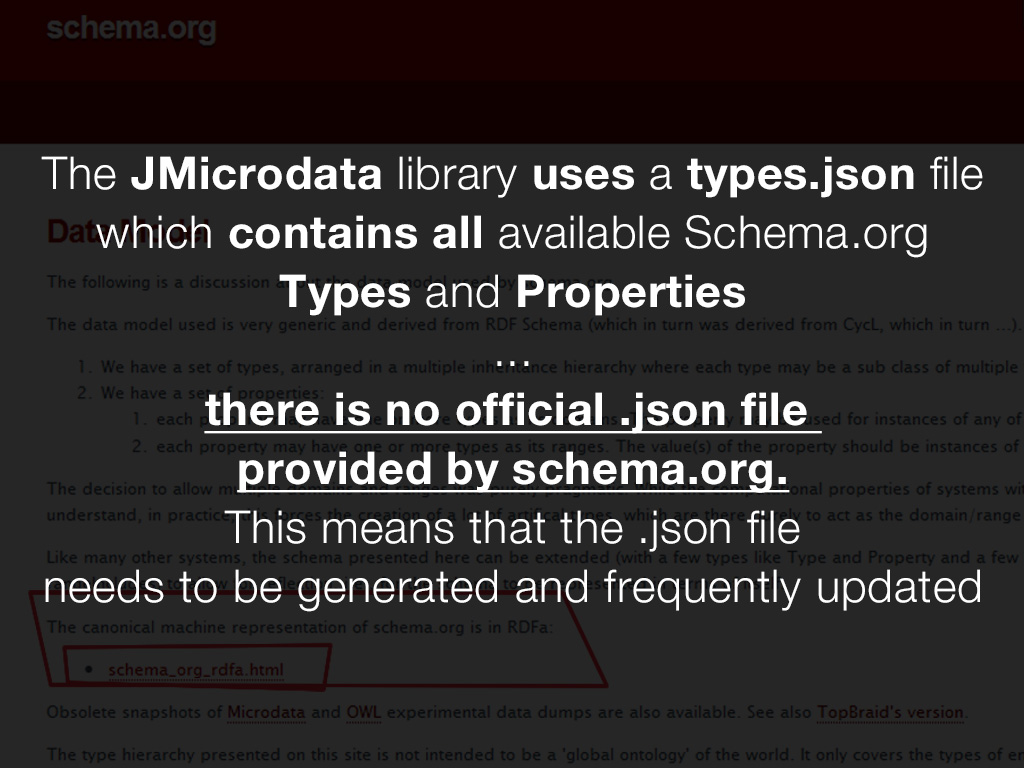
In order to generate valid semantics (because with an improvement we don’t want to create a disaster) we need a database somewhere where to check if the semantic code is valid. A database could be a compressed .json file containing all the available Types and Properties provided by schema.org. Actually, this is what JMicrodata does - it uses a .json file containing everything in order to check the semantic validity, and that file is generated with the Spider4Schema web bot.
Unfortunately there is no official .json file provided by schema.org, but they are working on that,so, for the time being, the file needs to be generated externally. Another problem is that since it is a new standard, the schema.org specifications update frequently, this means that the types .json file need to be generated and updated frequently.
Problem two:
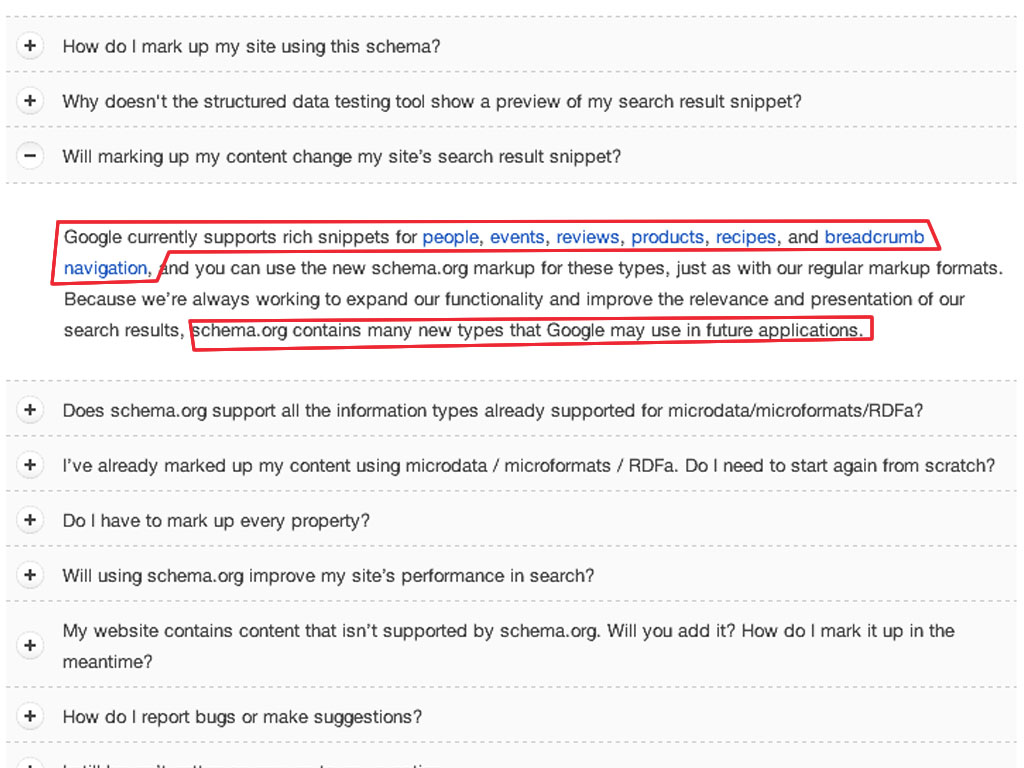
Google currently supports rich snippets for people, events, reviews, products, recipes, and breadcrumb navigation. But they are working on supporting new types. The story is the same for Yandex, Bing and Baidu, they support just few of them. So in short, currently we don’t need to support all available types.
Problem three:
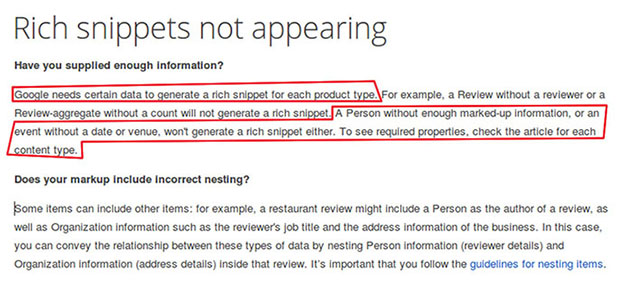
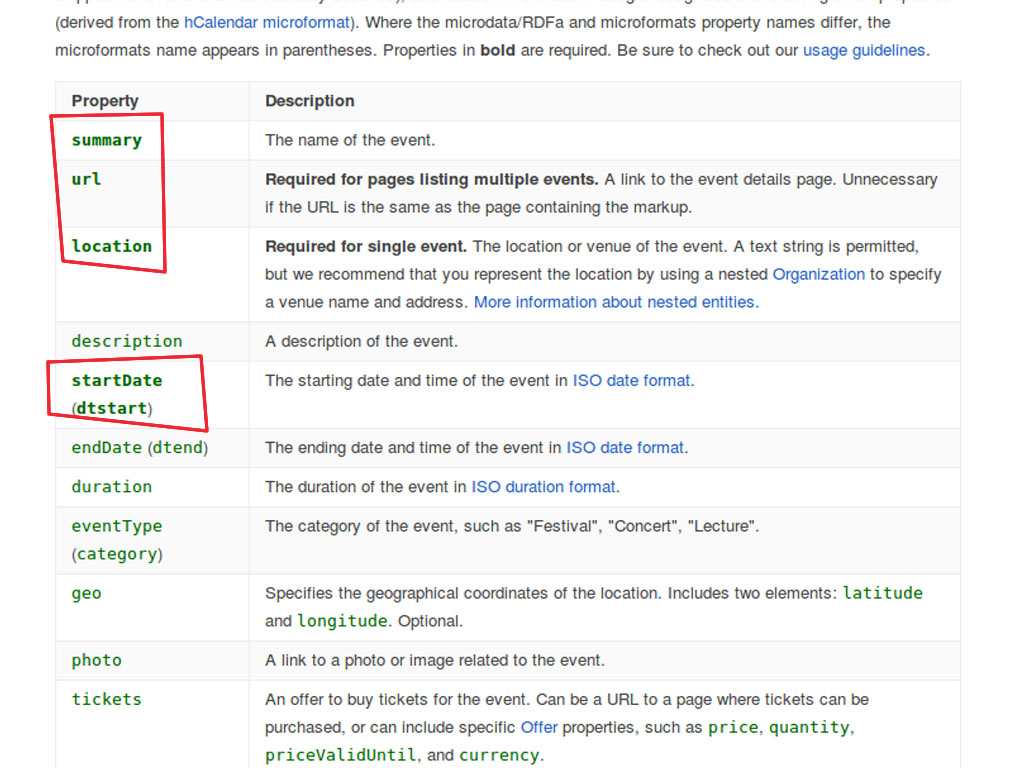
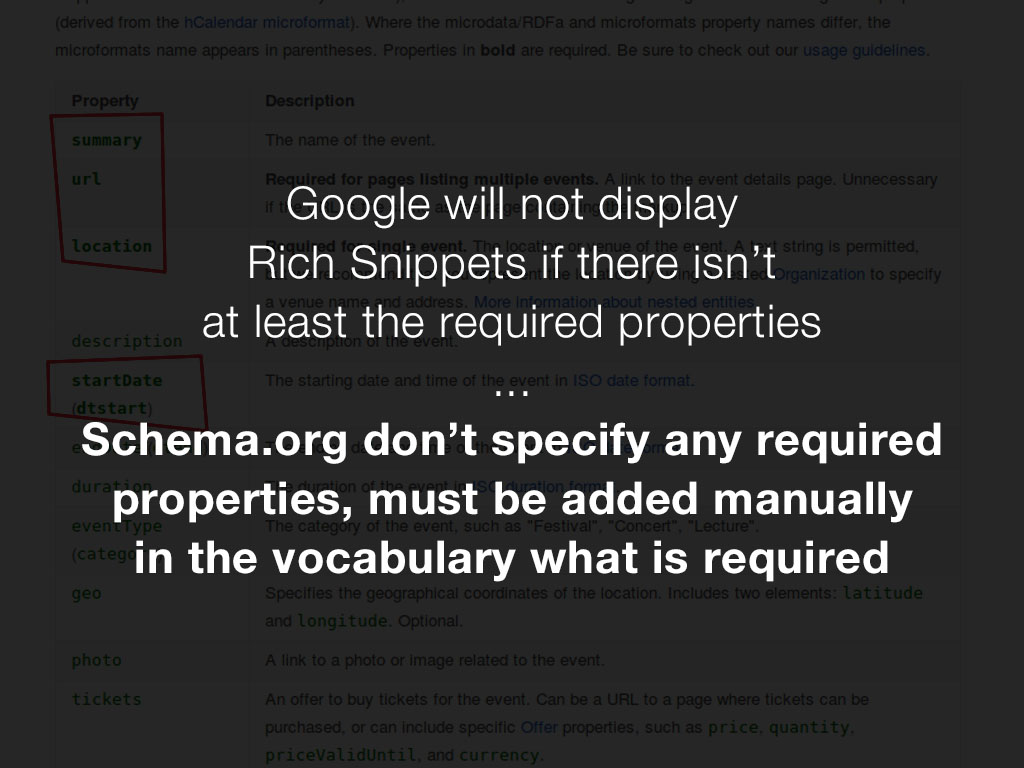
Google needs certain data to generate a rich snippet for each supported type, it will not display rich snippets if the mandatory properties are not present, unfortunately schema.org don’t provide any required properties and it isn’t standardized.
If we implement structured data, we want to ensure that the rich snippets show - so we must ensure that the mandatory data is provided. To reduce the likelihood of this occurring, we need to ensure that when a publisher saves an article, the mandatory properties are being provided as a bare minimum. To see and check which properties are required we need to have them somewhere, a solution could be the types.json file. If that is the way, we need to specify manually which of them are required in the types.json file, Google don’t provide any API to grab that list automatically. The same is true for other search engines.
Problem four:
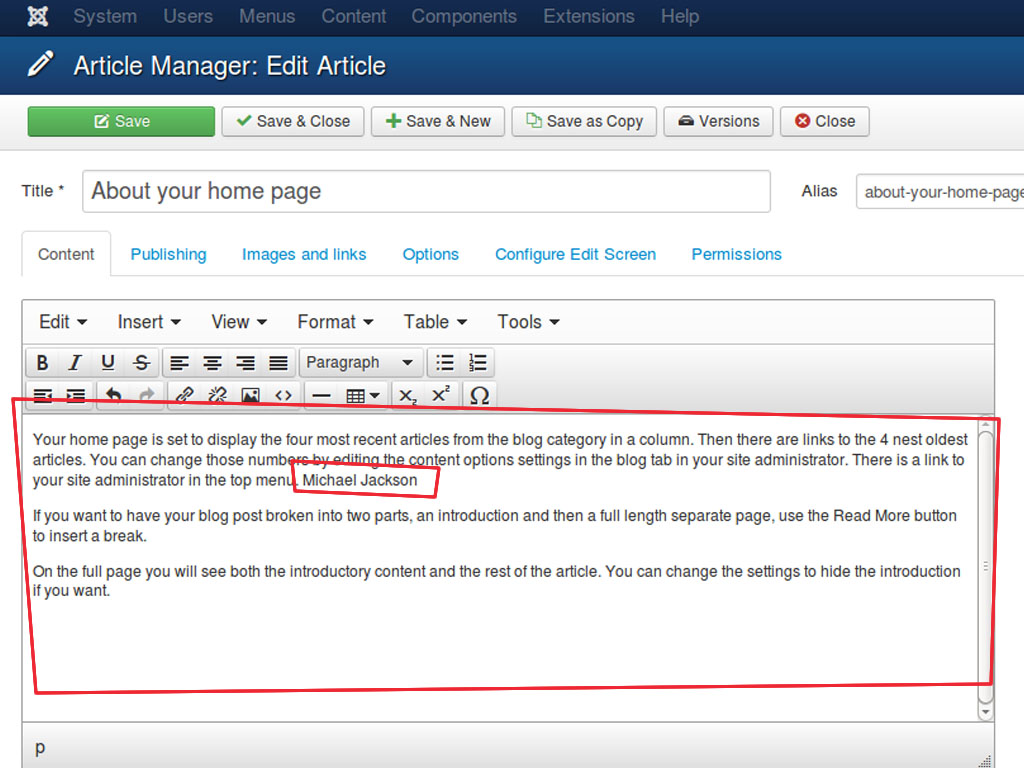
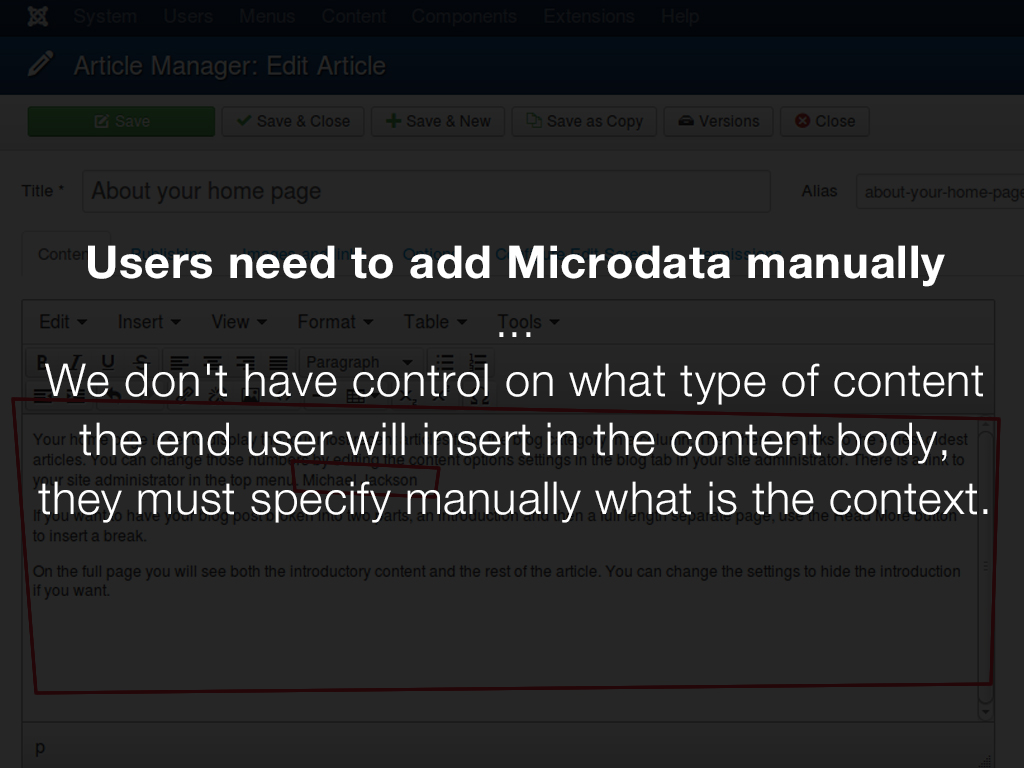
As mentioned at the beginning of the article, humans need to add manually additional information to explain to a machine what the page is talking about. Even if we can automate that process in some parts, there are parts that we can’t control, one example is the content editor. We don’t have control on what type of content the end user will insert in the content body, they must specify manually what is the context at a nested level.
So a quick summary:
There is no silver bullet to completely generate Structured Data (Microdata, RDFa) automaticly. Currently there aren’t strong standards, every search engine support just few Types and requires some mandatory properties in order to display rich snippets, and Schema.org don’t provide any of these and neither a .json file containing everything.
It’s a young technology, standards update day by day, and things need to be updated frequently.
Solutions
Even if it is not possible to fully automate the generation of Structured Data (Microdata, RDFa) completely automatically, it can be done partially by using the JMicrodata library, which allows you to display valid semantics and with the use of fallbacks to change the page type dynamically. But that library isn’t so easy and intuitive to use.
Thanks to an idea by Thomas Hunziker, a Joomla 3.2+ system plugin was created to simplify the JMicrodata library use in the CMS. Basically the plugin parses the HTML markup and convert the data-* HTML5 attributes in Microdata semantics. The data-* attributes are new in HTML5, they gives us the ability to embed custom data attributes on all HTML elements. So if you disable the library output, the HTML will still be validated.
You can download and find the plugin documentation here.
(You can also download and try the same plugin containing the new version of the Microdata library, which contains a JRDFa library. So with one button you can simply switch between Microdata and RDFa Lite 1.1 semantics)
The usage syntax is simple:

You can use that data-sd HTML5 attribute everywhere: in your views, templates, article editor, anywhere where you are allowed to modify the html.
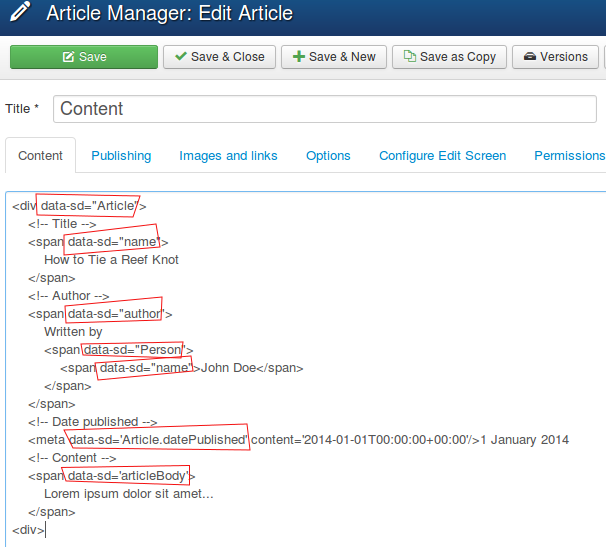
Before rendering the web page, the plugin will search for the data-sd attributes and replace it with the generated microdata semantic.
Currently this plugin doesn’t support fallbacks and multiple data-* suffixes, but it should evolve in something like this (not implemented yet):

Which will allow adding fallbacks and custom suffixes to search and convert, so any third-party developer could add and use his own suffix. But this solution is still complex for someone who is not an HTML and Microdata/RDFa expert.
Now I’m working on a implementation proposed by YouJoomla.com, which at the moment isn’t implemented yet, but should arrive soon! Below the very simple Proof of concept of the implementation:
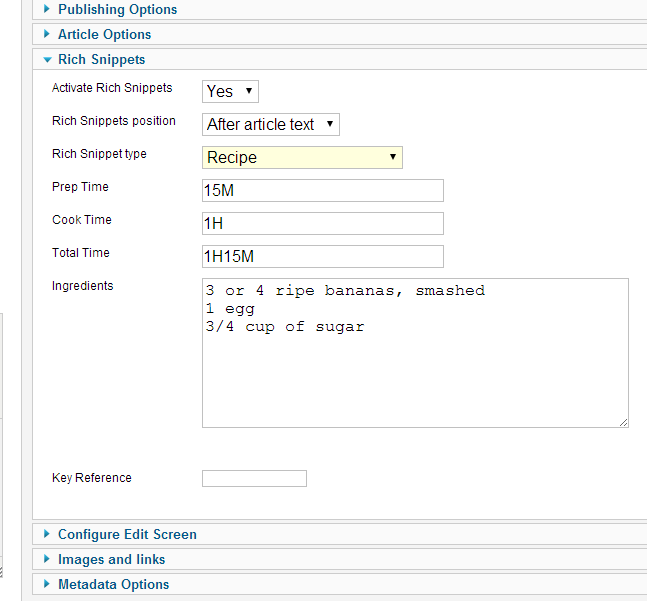
From the article options, you just select one of the supported types by Google and fill the properties. Also, if you use that feature, you will not be allowed to save the content before you insert the mandatory fields required by Google, this way rich snippets will be displayed on the SERP.
From the frontend, below is how that information will be displayed:
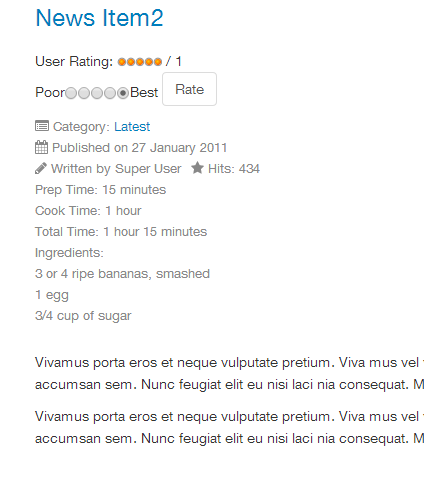
Conclusion
By using both implementations, the editors will be able to add Structured Data in a simple way, the developer could use the API in their own extensions, and the SEO expert to add easily from the Editor. There is still work to be done, with many discussions and experimentations having already taken place. The new version of the library supports RDFa semantics, so you can choose between Microdata and RDFa, plus there is a system plugin that allows you to use and add Structured Data globally. No pull requests have been made yet, but by the end of the GSoC 2014 program the new updates will be proposed to be inserted in the core of the project.
Also thanks to: Ruth Cheesley, Matt Thomas, Thomas Hunziker, YouJoomla.com and the community.
Some articles published on the Joomla Community Magazine represent the personal opinion or experience of the Author on the specific topic and might not be aligned to the official position of the Joomla Project
About the author
By accepting you will be accessing a service provided by a third-party external to https://magazine.joomla.org/
Comments